从“看看”
到“做到”_
视觉化采集的闭环:如何将碎片化信息固化为系统化行动方案。
在这个视觉信息过载的时代,我们的手机相册往往成为了灵感的墓地:街角的活动海报、社交媒体上的学习清单、工作会议的随手记。然而,绝大多数这类瞬间被捕捉的“灵感”,最终都难逃**“截图即收藏,收藏即吃灰”**的心理陷阱。这种断裂的心理闭环,本质上是由于非结构化图像信息与高度结构化行动清单之间的转换成本(认知负荷)太高。
从像素识别到“模态理解”的范式转移
Tudo的Vision功能并非基于过时的规则OCR,而是以**多模态大模型(Multimodal LLM)**为底层逻辑。这不仅是技术的升级,更是范式的转移。传统的OCR止步于“将像素识别为字符”,而**多模态解析**则能像人类专家一样,“理解”图像的视觉语境。当你拍摄一张复杂的白板讨论记录时,Tudo不仅在读取文字,它还在识别信息的层级、逻辑的关联,以及隐藏在乱序笔触背后的“下一步行动”意图。
这种向**“上下文智能(Contextual Intelligence)”**的跨越,消除了手动搬运与二次加工信息的摩擦,确保每一个视觉刺激都能瞬间转化为生产力系统中的确定节点。
视觉信息解析逻辑
分析非结构化手写草稿、复杂图表或碎片化的网页截图。
- 识别语义层级结构
- 解析隐含的日期与截止时点
- 建议最相关的项目分类
从意图到行动的执行
打破视觉与文字的壁垒,生成具备语义关联的Todo任务。
- 原子化的任务拆解
- 自动化的优先级分配
- 与现有工作流日志的深度整合
端云协同:隐私优先的安全协议
作为一款专业级工具,Tudo将数据的完整性与私密性视为生命线。通过采用**端云协同的处理模式**,我们将设备端的实时效率与云端最高规格的多模态解析能力结合。这确保了用户的视觉数据在享受世界级模型能力的同时,始终处于受保护的私密状态。每一个处理环节都透明可溯,让你的“第二大脑”不仅强大,而且绝对安全。
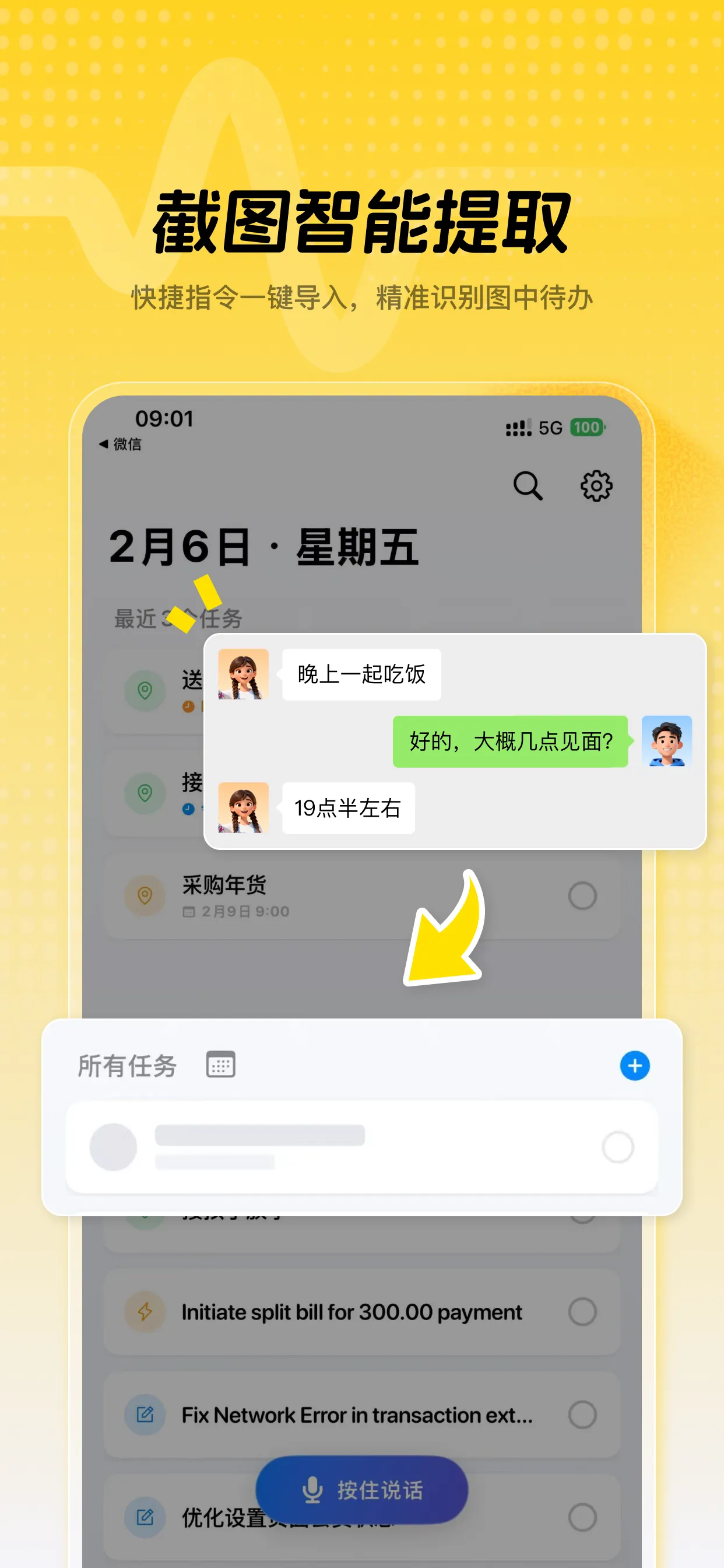
打破认知僵局,赋能行动
真正的效率,不在于你收集了多少信息,而在于有多少信息被你**转化**。Tudo的视觉采集功能,旨在彻底打破非结构化信息带来的认知僵局。通过极低效的录入门槛,我们将日常每一个“看见”的行为,转化为推动项目进展的价值步进。你不再是在存档灵感,而是在执行灵感。