世界を見て、
実行する。_
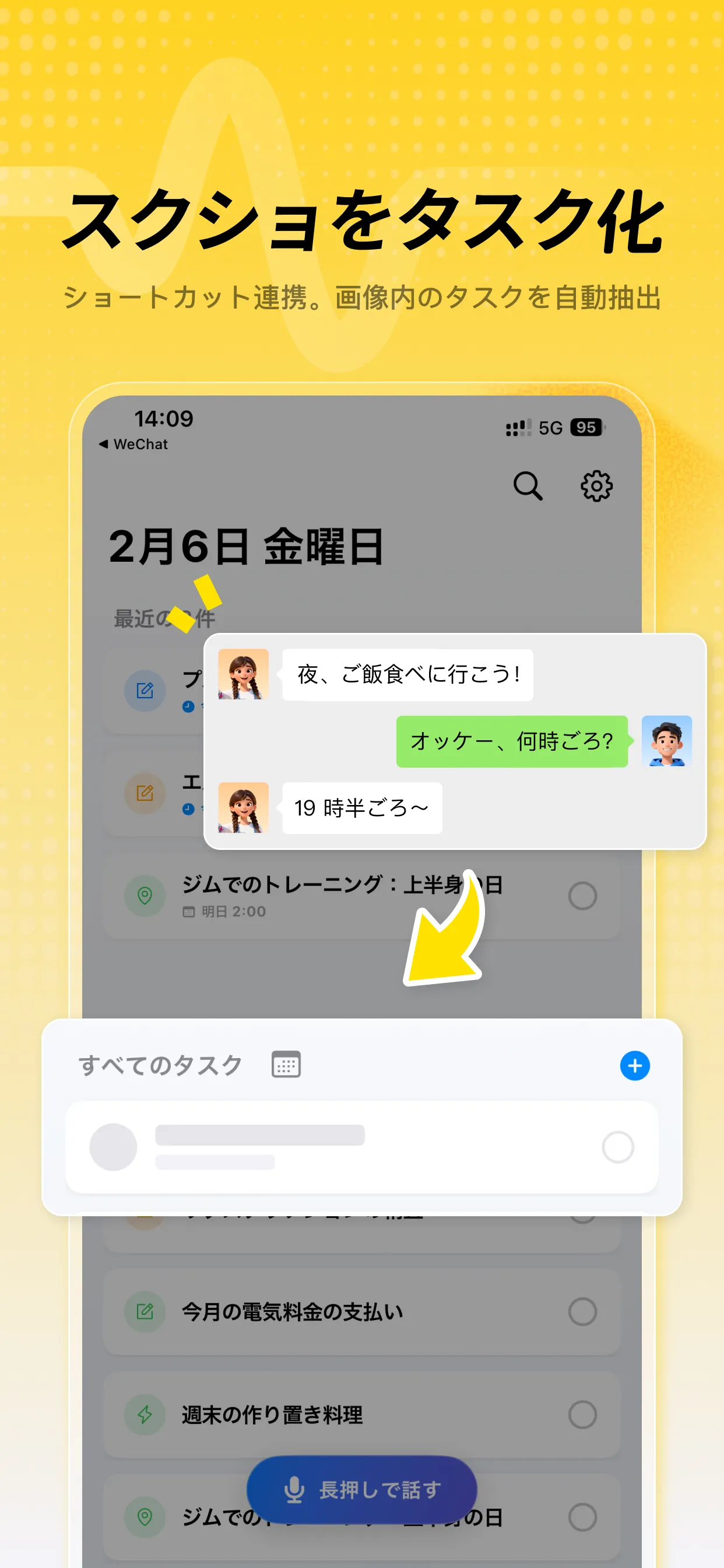
視覚的捕捉のループを閉じる:断片的な情報をシステム化された行動プランへと変換。
視覚情報が過多な現代において、私たちのカメラロールはしばしばインスピレーションの墓場となります。街角の展示会ポスター、SNSで見つけた学習リスト、仕事のメモ。しかし、こうした情報の大部分は、キャプチャされたまま埋もれてしまう**「キャプチャして忘れる」**習慣に陥っています。この断裂した心理的ループは、非構造化された視覚情報から構造化されたアクションプランへの移行コスト(認知負荷)が高すぎるために生じます。
ピクセル認識から「モーダル理解」への転換
TudoのVision機能は、旧来のルールベースのOCRではなく、**多模態大模型(Multimodal LLM)**を基盤としています。これは単なる技術のアップデートではなく、パラダイムシフトです。従来のOCRが「ピクセルを文字として認識する」ことに終始していたのに対し、**多模態解析**は、人間のように画像の視覚的文脈を「理解」します。ホワイトボードの複雑な図案を撮影した際、Tudoは単に文字を追うのではなく、情報の階層、論理的なつながり、そしてその背後にある「次に何をすべきか」という意図を瞬時に抽出します。
この**「文脈的インテリジェンス(Contextual Intelligence)」**への移行により、手動での整理に伴う摩擦が解消され、あらゆる視覚的刺激が即座に生産性システムの確実なアクションとして定着します。
視覚情報の解析プロセス
非構造化された手書き草稿、複雑な図表、Webの断片的なスクリーンショットを解析。
- 意味的な階層構造の特定
- 文脈から暗示された期限の抽出
- 最適なプロジェクトカテゴリの提案
意図からアクションへの変換
視覚とテキストの壁を打ち破り、意味的にリンクされたToDoとサブタスクを生成。
- アトミック(最小単位)なタスク分解
- 自動的な優先順位付け
- 既存のワークフローへのシームレスな統合
プライバシーを守るハイブリッド・プロトコル
プロフェッショナルなツールとして、Tudoはデータの完全性とプライバシーを最優先事項としています。**ハイブリッド処理モデル**を採用することで、デバイス上の効率的な処理と、セキュアなクラウド上での高度な多模態解析を組み合わせています。これにより、最高峰のAI能力を享受しながらも、視覚データは非公開のまま保護されます。すべてのプロセスは透明であり、あなたの「第二の脳」の安全性を保証します。
認知の停滞を打破し、行動へ
真の効率とは、どれだけ多くの情報を「集めたか」ではなく、どれだけ多くの情報を**「変換できたか」**で測られます。TudoのVision機能は、非構造化情報による認知の停滞を打ち破ることを目的としています。捕捉のハードルを下げることで、日常のあらゆる「見る」という行為を、プロジェクトを前進させる価値ある一歩へと変貌させます。もはやインスピレーションを保存するだけではありません。それを実行に移すのです。